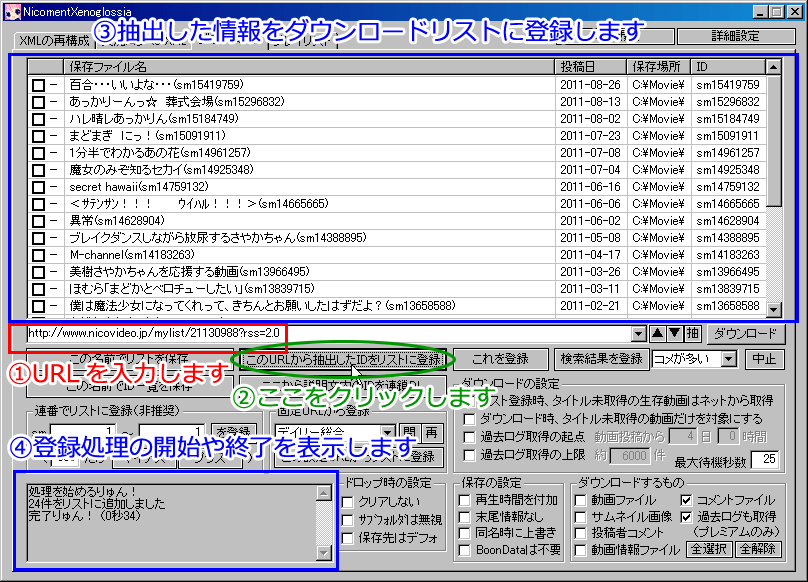
このページは、当ツールの挙動の説明としては大変重要なのですが、ちょっと難しいかもしれない内容になります(※上級者向け)。
・「ニコニコ動画の各ページから、ダウンロードリストに動画を登録する方法」では、マイリストやランキングのURLからリストに登録する方法を紹介しました。
(ニコニコ動画から指定されたURLのHTMLやRSSを取得して、そこに書かれている動画名などの情報を読み取ります)
・基本的には、「動画のID」を抽出するだけなら、たいていのURLから可能です(※「UTF-8」か「シフトJIS」のページのみ)
・しかし、マイリストやランキングのページ以外だと、「動画のID」は抽出できても、「動画名」や「投稿日」などの情報をHTMLから読み取れない場合が多いです。
・そのような場合、改めてネットから「動画名」などを取得すると、ちょっと効率が悪いです。
・なので、そのようなときは、次の方法で、HTMLやRSSから「動画名」や「投稿日」を読み取る方法を設定してみてください。
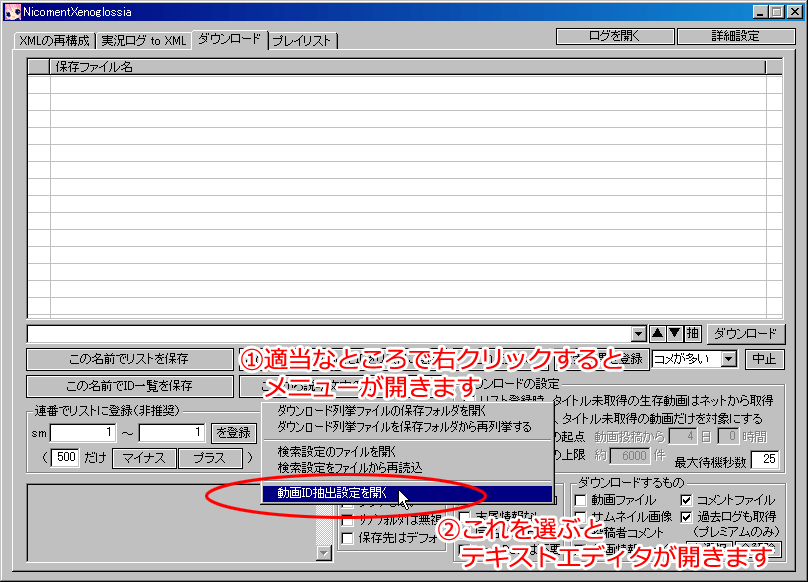
・上の操作で、設定ファイルがテキストエディタで開かれます。
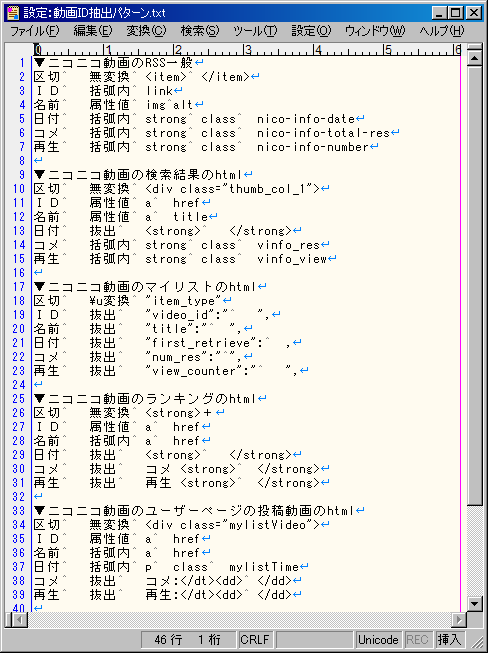
・意味不明に見えると思いますが、ここを書き直したり書き足したりすれば、URLから情報を抽出する方法を変更できます。
・「▼」は、ひとつの抽出設定のはじまりのサインになります(「▼」のあとに続く文字列は何でも構わないので、自分が分かりやすい設定名を書いておきます)
・抽出設定の数は、いくつ増やしても構いません。
・以下、この設定について説明していきます。
・さて、「このURLから抽出したIDをリストに登録」というボタンが押された場合、NicomentXenoglossiaは、指定されたURLにアクセスして、HTMLやXMLのテキストデータを取得します。
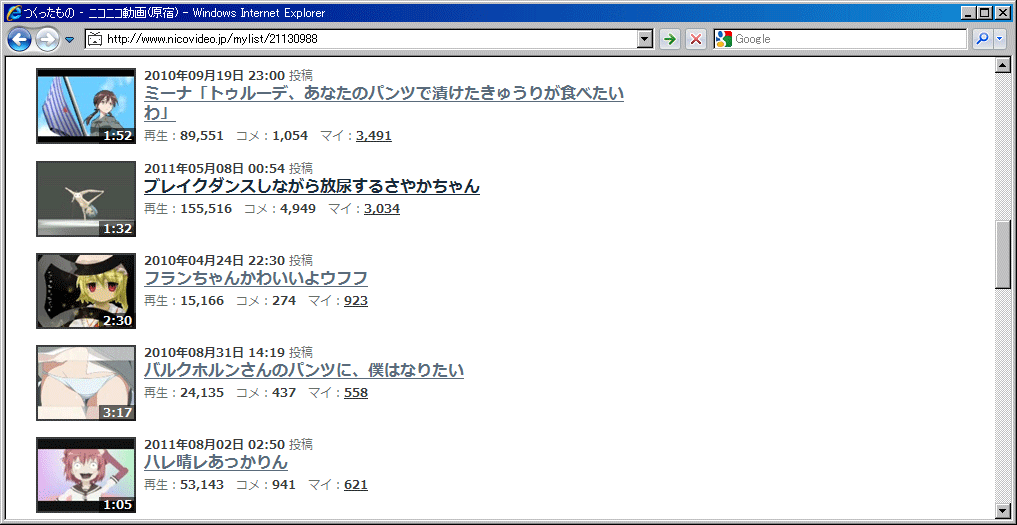
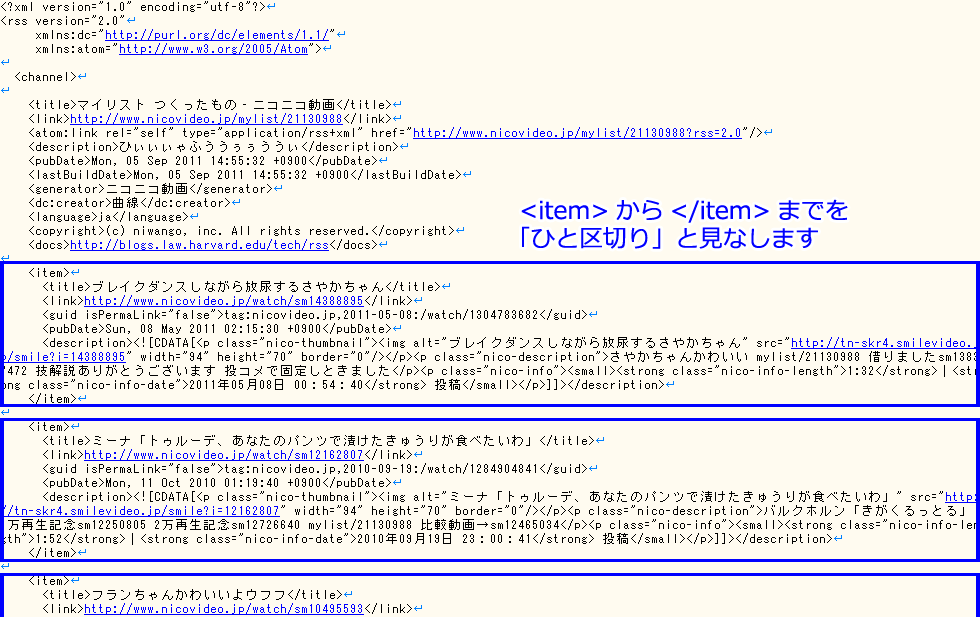
・たとえば、このマイリスト( http://www.nicovideo.jp/mylist/21130988?rss=2.0 )を指定されると、NicomentXenoglossiaは指定されたURLから、次のようなテキストデータを取得します。

・NicomentXenoglossiaは、この中から動画の「ID」「名前」「投稿日」などを探して、ダウンロードリストに登録します。
・上の例の場合だと、次のような部分から、情報を取得します。

・ただ、こういった情報が、どこにどういう風に書かれているかはURLによって違います。
・そこで、先ほどの設定ファイルには、「このURLなら、この情報が、ここにこういう風に書かれている」というパターンが、あらかじめ記録しています。
(謎の様式だと思いますけど、そういうパターンが書いてあります)
・NicomentXenoglossiaは、「今回のURLに対して、どのパターンを適用すれば良いか」みたいなことは判断せず、単純に、この抽出設定を上から順番に全部試していきます。
・そして、設定のどれかで抽出に成功したら、その抽出結果をダウンロードリストに登録して、処理を終わります。
(※もしも、すべての抽出設定で失敗した場合は、とりあえずテキストデータ全体から「動画IDっぽい文字列」をすべて探して、その結果をダウンロードリストに登録します)
・そんなこんなで、「このURLなら、ここにこういう風に情報が書かれている」というパターンを設定しておけば、そのURLからのダウンロードリストへの登録がスムーズになります。
・以下、その具体的な書き方を説明します。
・まず、それぞれの抽出設定の最初に、「区切」というのがあります。
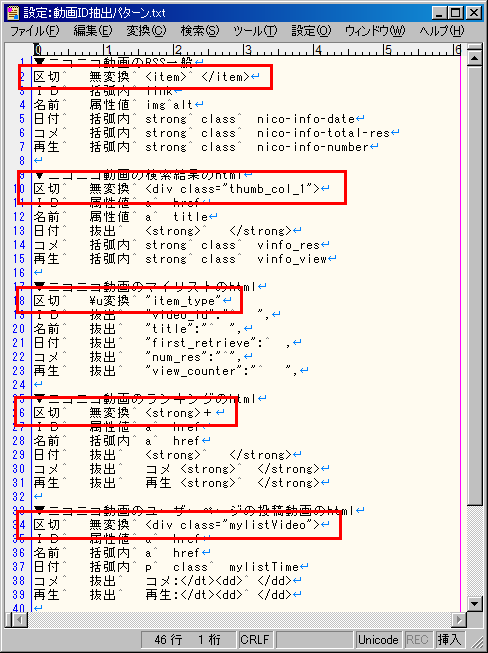
・一番上の「区切」のところには、「<item>」「</item>」と書いてありますが、これは「<item>」で始まって「</item>」で終わる部分を「ひと区切り」とする、という意味です。
・NicomentXenoglossiaは、それぞれの「ひと区切り」の中から、各要素をひとつずつだけ抽出します。
・つまり、「ひと区切り」に2つ以上のIDが含まれていても、1つめ以外は無視されます。
・なお、上の例では、「ひと区切り」の「始まり」と「終わり」(「<item>」と「</item>」)を指定しましたが、それ以外に、「ひと区切り」の「始まり」だけを指定する方法もあります。
(一番上のところ以外は、ひと区切りの「始まり」だけを指定しています)
・たとえば、もしも「<item>」と「</item>」を指定するかわりに、「<title>」とだけ指定したなら、「ひと区切り」は次のようになります。

(※ある「<title>」に対して、「次の<title>」がない場合は、その「ひと区切り」の終わりはテキストの一番最後になります)
・上の区切り方だと、一番最初の「ひと区切り」には、動画の情報が含まれていませんが、特に問題はありません(処理中にスルーされるだけです)
・あと、設定の「区切」のところには、「無変換」とか「\u変換」とかいうのがありますが、通常は「無変換」にしてください。
・URLから取得できるHTMLのソースが次のようになる場合は、「\u変換」にしてください。

(※「\u変換」にすると、「\u+16進数の数字」になっているところを、普通の文字に置き換えて処理します)
(※※正直なところ、この2つを設定で区別することが有効な場面には一度も出会ったことがなく、別に分けなくて良かったと思っております)
・さて、設定の次の部分では、「ID」「名前」「日付」「コメ」などの情報を、どのように抽出するかを書いています。
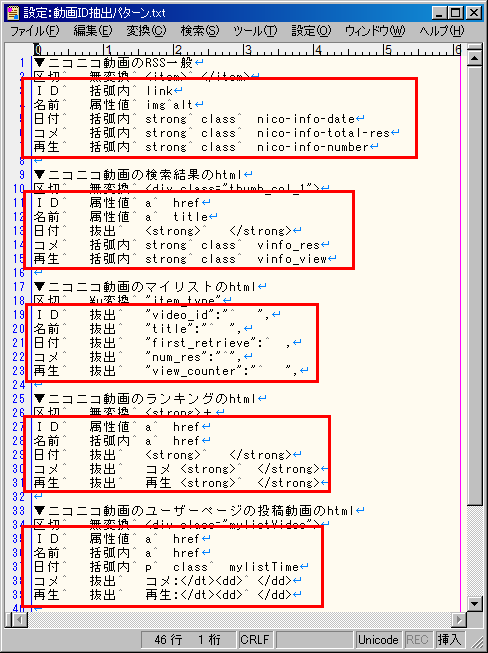
・この設定に基づいて、それぞれの「ひと区切り」から、情報を抽出することになります。
・たとえば、こんな「ひと区切り」があるとして……。

・「ID 括弧内 link」という設定の場合は、最初に見つけた「link」タグの中身(「<link>」から「</link>」で囲まれた部分)から、動画のIDを抽出します。

(上の例だと、「http://www.nicovideo.jp/watch/sm14388895」という部分を指定しています。ツール側の処理で、そこから「sm14388895」というIDを抽出します)
・「<link>」から「</link>」で囲まれた部分から、IDらしき文字列を抽出できない場合は、この「ひと区切り」からは情報は得られなかったということでスルーします。
(「ひと区切り」の中にそもそも「<link>」や「</link>」が存在しない場合も、スルーします)
・もしも、すべての「ひと区切り」をスルーした場合は、この抽出設定では合わないということで、次の抽出設定を試します(次の「▼」に移ります)
・さて、「日付 括弧内 strong class nico-info-date」という設定の場合は、最初に見つけた、値を「nico-info-date」にされた「class」属性を持つ「strong」タグの中身から、動画の投稿日を抽出します。

・上の例では、「ひと区切り」の中に、2つの「strong」タグがありますが、「class="nico-info-date"」を持つ「strong」タグは、赤色で囲ったところが最初なので、その中身である「2011年05月08日 00:54:40」という部分から、投稿日を抽出します。
・上の例で、もしも「日付 括弧内 strong class」という設定にしているならば、最初に見つけた、「class」属性を持つ「strong」タグの中身から、日付を抽出しようとします(その場合は、「<strong class="nico-info-length">1:32</strong>」が最初に条件を満たすので、「1:32」という部分から投稿日を抽出しようとして失敗します)
・「名前 属性値 img alt」という設定の場合は、最初に見つけた、「alt」属性を持つ「img」タグの、その「alt」属性の値を、動画の名前にします。

・上の例では、「ブレイクダンスしながら放尿するさやかちゃん」を、動画の名前として抽出します。
・上の例で、もしも「名前 抜出 <title> </title>」という設定にしているならば、最初に見つけた「<title>」から、次の「</title>」までのあいだの部分を、動画の名前にします。

(「<title>ブレイクダンスしながら放尿するさやかちゃん</title>」が最初に条件を満たすので、「ブレイクダンスしながら放尿するさやかちゃん」を動画の名前として抽出します)
・「括弧内」と「属性値」の意味が分からない場合は、全部「抜出」で指定すれば、たぶんなんとかなります。
・上の例(マイリストのRSS)では、「名前 属性値 img alt」と指定しても、「名前 抜出 <title> </title>」と指定しても、同じ「ブレイクダンスしながら放尿するさやかちゃん」を抜き出します。
・しかし、マイリストのRSSではなく、ランキングのRSSの場合だと、<title>タグまわりは「<title>第1位:ブレイクダンスしながら放尿するさやかちゃん</title>」みたいな記述になっています。
・ランキングのRSSに対して、「抜出 <title> </title>」で抽出すると、その「第1位:」の部分が含まれてしまうので、デフォルトの設定ファイルでは、「属性値 img alt」を使っています。
(そのほか、マイリストなら「日付 括弧内 pubDate」でも大丈夫だけど、ランキングでは pubDate タグの中身がランキング更新の日付になっている……といった違いがあります)
・動画の名前は、「抜出」「括弧内」「属性値」などで指定した部分を、加工せずにそのまま使います。
・コメント数は、「抜出」「括弧内」「属性値」などで指定した部分のうち、数字だけを抜き出して使います。
・IDは、「抜出」「括弧内」「属性値」などで指定した部分から、IDっぽい部分を抜き出して使います。
・日付は、「2011-07-15~」「2011/07/06~」「2011年07月17日~」「Fri, 22 Jul 2011 13:18:47 +0900」「1225457829」(UNIXタイム)みたいな部分を指定できていれば、それを変換して使います。
・「区切」と「抜出」のみ、設定ファイルに<%改行%>と書くとCRLF、<%タブ%>と書くとタブとしてあつかいます。
・設定ファイルは、次のような書き方もできます。
▼ニコニコ動画のRSS一般
区切 無変換 <item> </item>
ID 括弧内 link
名前 属性値 img alt
日付 括弧内 strong class nico-info-date
コメ 括弧内 strong class nico-info-total-res
コメ 括弧内 strong class nico-numbers-view
再生 括弧内 strong class nico-info-number
・この場合、コメント数の抽出については、最初に「括弧内 strong class nico-info-total-res」で試して、もしも取得できなければ、次に「括弧内 strong class nico-numbers-view」を試します。
・「区切」以外の指定は、このように、いくつでも並べることができます。
・いくつ並べた場合でも、上から順番に試していって、なんらかの内容が抽出できた時点で、その内容で確定します。
・そんなこんなの処理の結果が、次のような「ダウンロードリストへの登録」になります。
※(2)と(3)のあいだで、「http://www.nicovideo.jp/mylist/21130988?rss=2.0」からテキストを取得して、「<item>」から「</item>」までの区切りごとに、最初に見つけた「link」タグの中身から動画のIDを抽出して、最初に見つけた値が「nico-info-date」になっている「class」属性を持つ「strong」タグの中身から投稿日を抽出して、最初に見つけた「img」タグに含まれる「alt」属性の値を動画名にする……みたいな処理を行っている感じです。
・なお、今回の例のURLには、「コメント数」の情報が含まれていませんでした。
(コメント数の情報は、「http://www.nicovideo.jp/mylist/21130988?rss=2.0」の中には書かれていません)
・なので、「コメント数」の抽出には失敗しているのですが、処理の結果としては、先ほどの画像のように、「ID」「動画名」「投稿日」をダウンロードリストに登録しています。
・そんな感じで、「コメント数」や「投稿日」は抽出できなくても、「動画ID」と「動画名」さえ抽出できていれば、抽出は成功したものとして処理を進めます。
・今回の例では、便宜上、コメント数が含まれない http://www.nicovideo.jp/mylist/21130988?rss=2.0 を指定しました。
・コメント数も取得したい場合は、http://www.nicovideo.jp/mylist/21130988?rss=2.0&numbers=1 と指定します。
・このあたりの仕様はニコニコ動画で使えるRSSフィードの一覧などをご参照ください。
・htmlやxmlの「タグ」というのがよく分からない場合は、「属性値」と「括弧内」は使わずに、すべてを「区切」と「抜出」だけで指定するのが、たぶん一番簡単です。
・いちおう、正規表現やスクリプトといった特別な知識は必要ないので、だれにでも設定できる……と良いのですが、正直なところ、むしろ普通にスクリプトとかで実装した方が分かりやすかったのではないかという気がしていないこともありません。ごめんなさい。
・ニコニコ動画の仕様変更などがあった場合も、「設定:動画ID抽出パターン.txt」と「設定:動画情報の取得.txt」の書きかえで、ある程度は対応できると思います。
・ver2.15以降は、設定を1行増やしました。
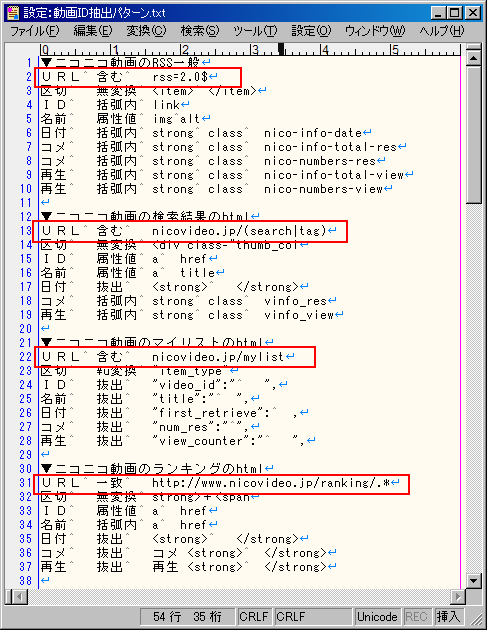
・「このURLから抽出したIDをリストに登録」というボタンが押された場合、NicomentXenoglossiaは、指定されたURLにアクセスして、HTMLやXMLのテキストデータを取得します。
・それから、そのテキストデータについて、設定されたパターンで動画IDやコメント数などを抽出できるか確かめていくわけですが、パターンに「URL」という設定がある場合は、アクセスしたURLがそれと適合する場合のみ、そのパターンでの抽出を試みます。
(アクセスしたURLがそれと適合しない場合は、そのパターンでの抽出をスキップして、次のパターンでの抽出に進みます)
・書式は、「URL」+「含む」または「一致」+正規表現となります。
・「含む」の場合は、アクセスしたURLが、指定の正規表現を含むならば(部分一致するならば)、適合と見なします。
・「一致」の場合は、アクセスしたURLが、指定の正規表現と完全に一致するならば、適合と見なします。
(性質上、通常は「含む」だけを使えば十分だと思います)
・なお、「URL」という設定がない場合は、そのパターンでの抽出を常に試みます(設定が存在してURLが適合した場合と同じ動作になります)